当前大模型强大的自然语言处理能力,极大地提升了各个领域的生产力,并且产生了各类新型的应用。在警情领域,大模型被用于提取警情的关键特征、分类警情、生成摘要、生成自然语言指令、自动问答等,以支持智能交互、分析和决策。
当前大模型强大的自然语言处理能力,极大地提升了各个领域的生产力,并且产生了各类新型的应用。在警情领域,大模型被用于提取警情的关键特征、分类警情、生成摘要、生成自然语言指令、自动问答等,以支持智能交互、分析和决策。
随着自然语言模型规模越来越大,预训练发布的模型其语言泛化能力很强,但是其专业能力无法胜任大部分领域的业务处理,需要微调(fine-tuning)、检索增强生成(RAG,检索知识库)等技术提升模型的领域技术能力。当前警情系统与大模型的集成解决方案如下:首先经预训练及微调方式得出大模型,其次警情系统调用大模型以实现自然语言理解(例如获取文本中实体要素)或自然语言生成(例如生成摘要),最后警情系统的应用层算子产生报告、预警或其它输出。该解决方案存在不足之处:自然语言大模型与警情系统相互独立,当前业务系统运行期间积累的知识无法提升模型能力,尤其对于警情而言,其特有的领域特征难以及时地赋能给自然语言大模型。针对这些不足现状,本文给出大模型自迭代的机制,使得大模型以持续优化的性能服务于警情领域。
一、方法论
警情领域中,每条警情均要求人工处置,因此警情系统具备了大模型预测与人工判断的便利条件,使得充分利用人工知识自迭代优化大模型成为现实。
自迭代大模型的方法论是:使用程序将经过人工矫正的预测结构化处理后生成新的样本,并过滤或置换样本库中错误或过时的样本,再定期或人工即时触发训练,生成新模型并且部署于系统,如图1 所示。
 图1
图1
对于无需矫正的预测,不涉及上述处理。此处大模型使用的样本库,在警情系统初始运行时是人工标注的数据集。在后续迭代则合并入矫正数据集。
人工标注或人工矫正不可避免有错标、多标或漏标的情况,样本库中含有此类数据时降低大模型的精度,因此要求使用“归并”流程识别并筛除此类样本。最后,迭代训练后产生模型,使用容器增量升级技术自动化地更新至应用系统。对于系统的使用者而言,不会冲断和影响业务。
二、初始样本和训练
(一)样本库
根据警情系统的需求以及大模型的功能,样本遵循固定的格式。训练的初始样本来源于人工标注,系统将其结构化入样本库作为初始数据集。
(二)训练方法及模型
警情领域提取警情特征、分类警情、生成摘要等大模型,不适合使用知识库(RAG)检索,更适合在预训练大模型基础上进行微调。因为知识库(RAG)更适合可以从外部信息检索中受益的任务,而微调更适合使用可用的标记数据使大模型适应警情领域。
根据具体的任务需求、计算资源、训练时间等因素选择微调方案。目前主流的微调方案如下:
1.LoRA(Low-RankAdaptation)
LoRA 的实现方法主要是在模型的权重矩阵中添加一个或多个低秩矩阵。这些低秩矩阵的秩通常远小于原始权重矩阵的秩,但足以捕获权重矩阵中的重要变化。在微调过程中,只优化这些低秩矩阵的参数,而保持原始权重矩阵不变,这样就可以用较少的参数和计算成本来调整模型的行为。其优点是轻量化、高效性,其缺点是效果损失。
= 轻量化:通过向模型中添加额外的低秩矩阵并仅训练这些矩阵,LoRA 显著降低了微调过程中的计算资源消耗。
= 高效性:LoRA 的低秩近似方法能够快速收敛,提高微调效率,缩短模型上线时间。
= 效果损失:由于低秩近似可能带来的信息损失,LoRA 在微调过程中可能会导致模型性能下降,特别是在处理复杂任务时。
因此LoRA 适用于对计算资源和训练时间有严格限制的场景。但是LoRA 具有一些设计和调整难度。这是因为LoRA 需要引入额外的低秩矩阵结构,在优化过程中要求平衡新任务的学习和原始预训练知识的保留。
2. 全参数微调(Full Fine-tuning)
Full Fine-tuning 的常用方法是将预训练模型的全部参数作为初始参数,然后使用新任务的数据集对模型进行训练。在训练过程中,会使用适当的优化算法(如梯度下降算法)来更新模型的参数,以使模型在新任务上的性能逐渐提高。其优点是性能优越、适用性广,其缺点是计算资源消耗大、训练时间长;如果新任务的数据集规模较小,Full Finetuning可能会导致模型过拟合。
= 性能优越:通过训练模型的所有参数,能够充分挖掘模型的潜力,实现更好的性能。
= 适用性广:不受限于增量矩阵的秩特性,适用于各种任务和数据集。
= 计算资源消耗大:需要训练模型的所有参数,计算资源消耗较大。
= 训练时间长:由于需要训练大量参数,训练时间通常较长。
因此全参数微调适用于对性能有极高要求,且计算资源和时间充足的情况。
3.Adapter Tuning
Adapter Tuning 通过在预训练模型的特定层上添加一个可学习的附加层(如线性层、非线性层等)来适应特定任务。这个附加层(即Adapter 模块)的参数是专门为了新任务而训练的,而原始预训练模型的参数在微调过程中保持不变。Adapter 模块能够在不改变整体模型结构的情况下,通过调整自身的参数来适应新任务。其优点是参数调整数量少、保留预训练知识,其缺点是需要额外的设计、可能无法捕获复杂特征。
= 参数调整数量少:通过在预训练模型的中间层添加轻量级的适配器模块,减少了参数调整的数量,同时还能保持与全量微调相当的模型性能。
= 保留预训练知识:主要的预训练参数受到保护,不会被大幅度改变,从而在特定任务上保留更多的预训练知识。
= 需要额外的设计:在将Adapter 模块插入到预训练模型中时,需要进行额外的设计和调整,以确保其与原始模型能够良好地融合。
= 可能无法捕获复杂特征:由于Adapter 模块的尺寸较小,它可能无法完全捕获到整个预训练模型的复杂特征,这可能会在一定程度上限制其性能。
因此Adapter Tuning 适用于希望尽可能保留预训练模型中的知识,Adapter Tuning 的设计相对直观,但需要仔细选择Adapter 模块的位置和结构,以确保其能够有效地适应新任务。
综合比较上述各种微调方法,全参数微调代价昂贵,Adapter Tuning 存在训练和推理延迟,而LoRA需要的内存和计算资源最少,经过专业的设计能达到高效的性能,因此选择LoRA 作为大模型微调方案。
LLaMA 是一个开源以及高效的大型预训练语言模型,它采用了Transformer 架构,并在海量文本上进行预训练。Llama 模型在处理各种NLP 任务时也展现出了强大的能力。LLaMA 模型通过预训练捕捉到了语言的深层结构和语义信息,能够准确理解文本的含义并给出恰当的回应。LLaMA 模型还具有可扩展性和易于与其他模块结合的特点,这为其在自然语言处理的应用提供了便利。因此选择一个基于LLaMA 的预训练大模型作为基础,使用LoRA 对基础模型进行微调,以适应警情领域的语言特点。
在微调过程中,使用上一节在警情领域标注的样本库对模型进行训练,使其学习到警情领域的特定知识和模式。
三、自迭代的预测与矫正
警情系统将训练后的模型部署上线,以API 接口提供预测服务。应用层通过API 接口调用对警情各维度实施预测,包括预测警情特征、预测警情分类、生成警情摘要等等。
应用层除了在页面显示模型的预测,而且开放人工矫正能力。在相同的警情文字上以不同样式展示预测与矫正,如图2 所示。
页面初始以零标注形式展示警情文字以及相关的属性。页面提供按钮以调用模型API 接口提取警情特征、分类警情、生成摘要等。
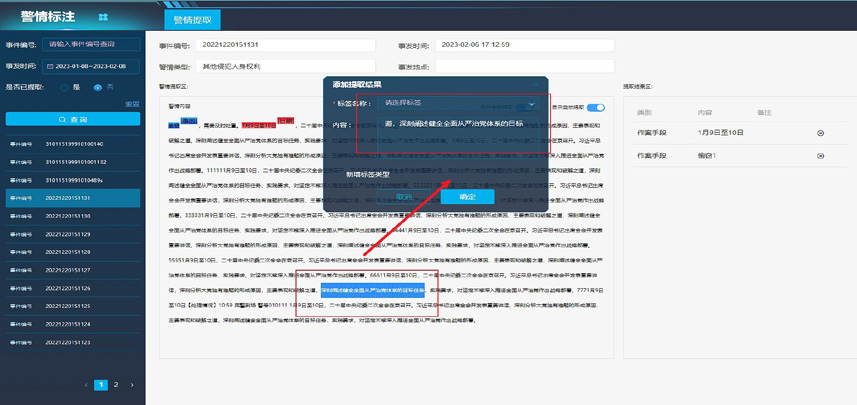 图2
图2
用户对于大模型不准确的预测结果可在页面矫正。例如可使用鼠标选择相应的文字指定警情特征,可改正警情摘要,可标准化警情地址。
实施人工矫正后的警情,系统按警情编号做出标记和存储,后续可默认将矫正后的内容以特别的样式展示给用户,以避免重复矫正的工作量。
四、自迭代的归并
警情系统定期地将人工矫正的数据集和样本库归并,或可以由用户即时触发自迭代的样本归并与模型的训练、部署。但是数据集的归并过程不是简单的合并,因为存在下列问题:
首先人工工作可能存在错误,例如错误的标签、多选择了文本、少选择了文本、输入错误文字。在样本库和矫正数据集中都可能存在此类错误。
其次数据集的比例可能不均衡,下表给出一段时期内按警情案由分类的比例。为了确保训练的性能,要求数据集按警情类型尽可能地均衡分布,避免出现过拟合的情况。
对于第一类人工错误的问题,通过使用训练后产生的模型重新预测所有样本,输出预测与样本的非一致报告,通过定期地人工分析非一致报告,筛选并纠正错误的样本。

对于第二类样本不均衡的问题,在样本中维护警情类型字段,当某警情类型的样本数量达到上限后,实施样本替换规则置换低质量的样本。样本替换规则综合考虑下列因素:警情内容长度、标注的token 数量、警情时间、是否矫正样本、矫正的token 数量、矫正人的准确率等等。
五、自迭代的训练和部署
定期或即时的大模型训练要求使用独立的服务器和适当的资源,以确保不影响线上的警情系统。训练后的模型打包入容器,再无缝地升级线上系统,如图3 所示以容器化管理大模型。
容器化的大模型要求支持集群模式,用户可以配置每个容器运行所需的内存、CPU 核数、显存、磁盘等资源,系统对于以API 接口方式提供的服务,支持负载均衡地路由API 接口调用至大模型集群的各个容器。
为了节省服务器资源,在空闲状态下经过一定的时间,系统能自动收缩集群中容器数量。反之,在忙时系统能自动扩展集群的容器数量直至最大配置数量。当系统达到负荷预警阈值时提前提醒管理员,以便人工介入处理。
 图3
图3
六、结语
由于警情领域内的知识和数据不断更新和变化,因此大模型也需要持续学习和更新以保持其性能。本文使用自迭代解决方案,自动化地实现了大模型的持续演进。当然,由于大模型算法自身换代周期频繁,LLaMA 2 于2023 年7 月发布, 而LLaMA 3 于2024年4 月发布,所以应周期地对大模型自身进行更新升级,才能使警情系统发挥其更高的性能。
文/ 徐卫军 邓宏飞 贾耀锋 深圳力维智联技术有限公司
参考文献:
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal Eric Hambro, Faisal Azhar,Aurelien Rodriguez, Armand Joulin Edouard Grave, Guillaume Lample. LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv: 2302.13971, 2023.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale,Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao,Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, ArtemKorenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra,Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian,Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, SharanNarang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023b. URL http://arxiv.org/abs/2307.09288. arXiv:2307.09288 [cs].
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large languagemodels. arXiv preprint arXiv:2106.09685, 2021.








 京公网安备 11010802042077
京公网安备 11010802042077